GitHub link: https://github.com/manicinc/logomaker
LLMS tested (GPT-4o, GPT-4.5, GPT–o1, Claude Sonnet 3.7, Gemini 2.5 Pro), default settings, 20$ / monthly plans. (No extended thinking, deep research, web search experimental plugins or memories used. Written in VS Code (not Cursor) with Copilot solving single line bugs).
(an experiment in title)
Intro
For the TL;DR go down here to see a list of useful lessons.
Time of writing I'm in software for the upper half yet still far decade. Comes a sly shock the necessity to say as there're non-junior engineers (mid-level, working for multiple years) who might've got away with never handwriting a class, function or even LOC with no gen AI.
A couple weeks back working on PortaPack (https://github.com/manicinc/portapack) I wanted to try logo designs and typefaces before a branding decision with the rest of the small team. We all have other projects and roles, so, the need for rapid prototyping.
I wanted cute and whimsical and got brutal hoping to get started online quickly; recs for free sites in top threads linked to paywalls, subscriptions behind dark patterns, like credit card info in the last step, or indenturing export quality to a unusable amount. Posts from a year back link to sites now living totally different experiences. Yeah updates are expected but this just didn't work for me, not freely.
In all capitalistic industries but especially software what often were useful products become more privatized.
We can't blame them. Server hosting even a year or two gets costly. How does a free tool that has use and traffic stay free?
BUT it is too common to lock in users and not be transparent on imposed limits. We see the manipulation misdirection means in login screens and app usability taking second precedence over signup windows, in hard-to-reach payment cancellation screens.

Things that drive users to annoyance and away from them.
So annoyance, wanting a quick (if dirty) UX, and a stir to see what'd happen drove me to pitch: Vibe code everything, full-stack and fully usable—every function written by an LLM, every design by an LLM. Nice 'n' easy quick 'n' dirty, this is just what everybody in the world is going to start doing if your apps have a dreadful enough experience.
This is just what everybody in the world is going to start doing if your apps have a dreadful enough experience.
I knew I could get a playground for different fonts showing me text options in probably an hour, even minutes depending on the model, prompt, and complexity. Maybe 1️⃣ prompt?
Logomaker🌈 has good scope. Not fintech, not healthcare, worst you waste time in a broken site with no ads and no data tracking. Who's Q/Aing this stuff? Logomaker, the app built 90% by ChatGPT? It's Q/Aed by no one, use with peril.

LLM sees, LLM does
I've a background in going to an art and design college. Art (even just visual art) is so encompassing logo designs I never specifically studied. I have Photoshop and Illustrator experience, but how they worked didn't interest me much. The features you see in the first Logomaker version weren't asked by me originally but designed by the LLM. Later on I refined and "architected" greater functionalities.
The iterative PM-esque process in product-driven prompts with technical-guided ones is needed to be worthy of use by a human in 2025.
On their own the LLMs from Anthropic (Sonnet 3.7), OpenAI (GPT-4o, GPT-o1, GPT-4.5), and Google (Gemini 2.5 Pro), all of which were extensively tested and ✨vibe coded ✨ with, could go just so far in self-improvement. You can't really keep asking a LLM to improve something for robustness or better UX and see better results after further than a few prompts, irrespective of token limits.
Is this a limitation of something like a creativity mechanism? Rigidly speaking there is no such thing in them. They predict next probable tokens in a sequence with a lot of parametrization so it's not always the same ouput. I mean thinking and creativity in a more abstract sense, which is easy to imagine (heh) as these mental structures are wildly malleable in humans anyway. Or if you're more interested in a philosphical discourse.
How can we be so sure anything we think is an original idea?

How can we be sure of our identities when the pseudoscientific You are the average of five people around you is commonly repeated it's dozens of pages of Google results?
Or is it natural consequence of LLMs' training? What happens if we get 10,000 product designers to write 10,000 user stories each? (100 billion user stories! 💣 This'd entail in a model that almost as large or in the ballpark of GPT-3). Good software now?

LLMs of course know what basic features go in a logo creator. We will see export options was done (and fully working from the LLM writing the exact dependency link needed from the CDN link for html2canvas.js, latest SHA hash intact and all) with multiple settings, though it was basic and didn't include SVG (which are complex, so it makes sense it's originally ignored unless prompted, as we asked for something working not advanced).
I didn't ask for specific types. We were writing this in JavaScript, adding types and interfaces would slow development down 2x (at start).
It's then simple to expand, and ask in the next prompt for additional exporting options of GIF and SVG. But if I didn't tell them to design adding new features in a way that, say, actively considered the UX with examples even, it would probably just give me a modal to render a GIF, SVG, and PNG, but all 3 as just buttons with working functionality and no additional flourish🪄💥. Tooltips, mobile responsive styles, sure, it won't go far beyond though, and there's lots of different paths needed for these formats to again actually be usable (by a semi-serious user).
| Format | Best For | Web Quality | Animation Support | Scalability | Styling Flexibility |
|---|---|---|---|---|---|
| PNG | Static images, transparency | ✅ Very High | ❌ None | ❌ Not scalable | ✅ Easy via container styles |
| GIF | Simple animations, loops, previews | ⚠️ Limited (256 colors) | ✅ Basic frame animation | ❌ Not scalable | ❌ Very limited |
| SVG | Logos, icons, responsive UI elements | ✅✅✅ Excellent | ✅ With CSS/JS or SMIL | ✅ Infinitely scalable | ⚠️ Advanced, but powerful. Very difficult. |
LLMs "like" to be conservative in generations. In coding, that's not good when you're getting incomplete scripts, or, in many cases, placeholder logic sneaking in even when instructed aggressively not to (keep this in mind down the line; is this a side effect of their architectures, or a condition by their providers?).
How can you guide a LLM to think about things like this, not just understanding nuances, but how to act accordingly? Only, it has to be.. without specifically listing that in example(s) form?
The thing about examples and LLMs. When you have few or limited ones, you run into constraints parallel to the same feature empowering one-shot or few-shot learning, the ability for an LLM to learn relatively easily from examples just in the context of the prompt itself without retraining.
The thing about examples and LLMs. When you have few or limited ones, you run into constraints parallel to the same feature empowering one-shot or few-shot learning, the ability for an LLM to learn relatively easily from examples just in the context of the prompt itself without retraining.
Say you need consistent JSON ({"Name", "Date", "Topic", "Location"}) parsed from some informal voice notes, and you use OpenAI.
In zero-shot, feeding "Last meet I had a sync with Jordan Thursday regarding new designs in the break room" from a recording might give inconsistent JSON like {"attendee": "Jordan", "subject": "new designs", ...}. The model guesses the format on prior patterns of scraped text data and metadata (which OpenAI scraped online sources, like Reddit, Twitter..), of course it's likely to get things twisted!
It's a natural limitation in LLMs. They get smarter with more training data, and that leaves more chances at capturing spam and noise (as well asmixing things up in their internal "reasoning"), causing hallucinations. In the case above, we will almost certainly get lowercased keys (instead of the capitalized ones as requested, or commonly used synonyms for those keys, sometimes, during interactions). So tech integrated around LLMs have to become more rigid to make up for their inflexibility.
You can give one example (one-shot learning) showing the input note -> desired JSON structure (here it'd be the input text and: {"Name": "Jordan", "Date": "Thursday", "Topic": "New designs", "Location": "Break room"}). A clear template to follow.
Add a few diverse examples (few-shot learning), more variations and how you want to handle them (like missing locations -> Location": null, or even metadata that can be auto-generated based on dynamic inputs, making fuller usage of the power of GPTs over typical transformer models), and this further helps the model give you what you want.
This powers function calling and typing libraries for LLMs, which combine these learning examples with continual validation and retry hooks. If this feels hackey, that's cause it is, and it is worrying as we see more APIs and tools assembled solely around prompt calls.
The rub?
Showing an LLM how you want something done with guided examples just makes it better at doing that or related tasks. It doesn't generalize from that a higher-level framework of thinking that would allow it to broadly be better.

It's not the best example but it's illustrative of the overarching problem of prompt engineering.
You can't both have a model be really good some particular things, and also even just kinda good at generalizing / extrapolating.
I could keep going with this writing style prompt, give more authors and passages and really switch it up. Vonnegut, King, Palaniuk. But all the LLMs do is attempt to adapt to every one of these styles at once, not necessarily generalize to become an actual peer to them. Even if you ask.

There're prompt engineering techniques (and a lot of proclaimed prompt engineers) positing to improve this kind of stateless mind of a LLM, but prompt hacks often just result in more coherent-sounding hallucinations.
Show me some code!
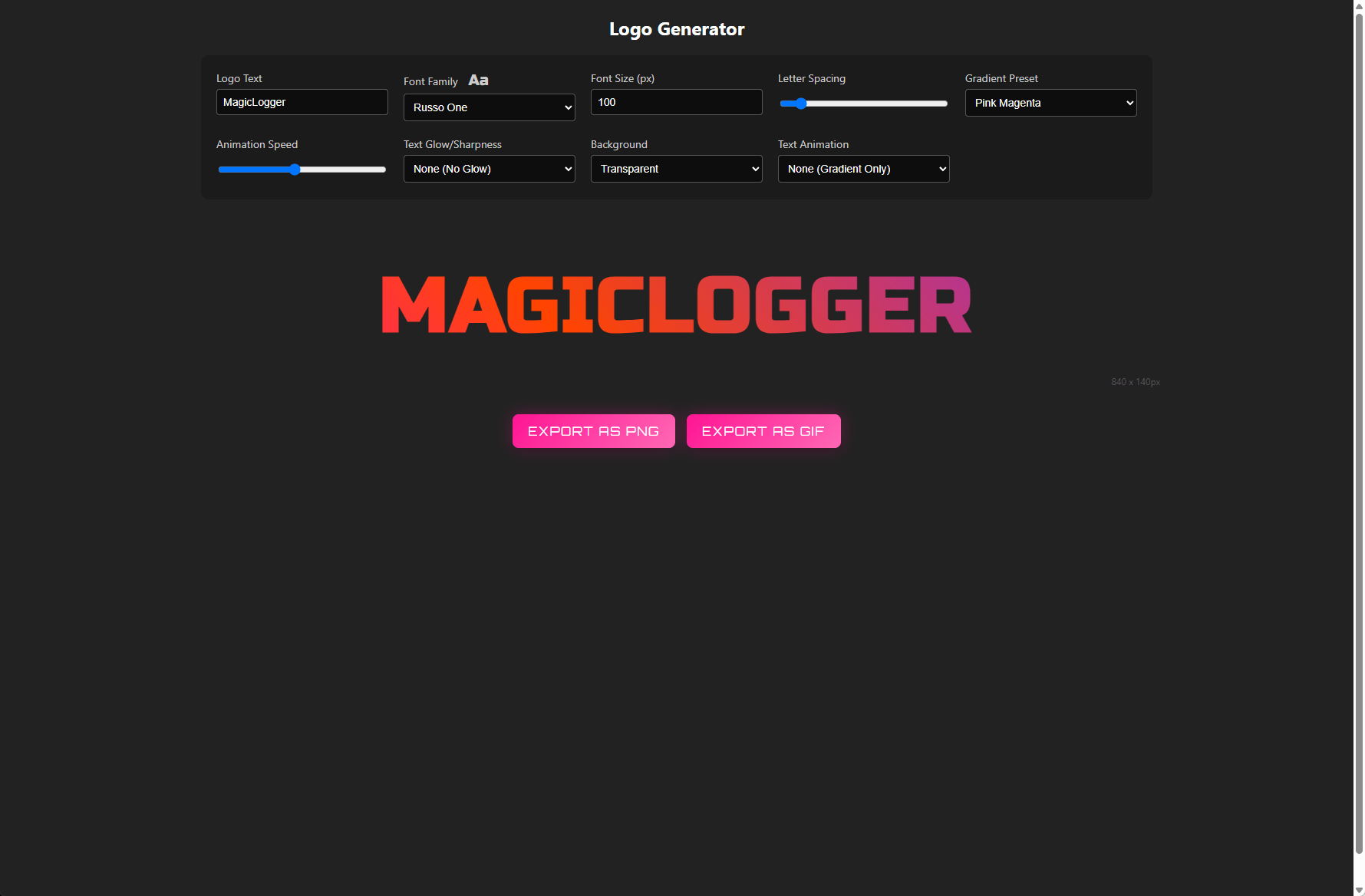
This code shows LLM "generating" the correct links for fonts (as well as other dependencies like https://cdnjs.cloudflare.com/ajax/libs/gif.js/0.2.0/gif.worker.js) in line 869, and starting the in-line CSS for styles for the logo creator to apply via UI selection, and an excerpt of the exporting logic.
html<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8"> <title>Logo Generator</title> <!-- Extended Google Fonts API --> <link rel="preconnect" href="https://fonts.googleapis.com"> <link rel="preconnect" href="https://fonts.gstatic.com" crossorigin> <link href="https://fonts.googleapis.com/css2?family=Orbitron:wght@400;500;700;900&family=Audiowide&family=Bungee+Shade&family=Bungee&family=Bungee+Outline&family=Bungee+Hairline&family=Chakra+Petch:wght@700&family=Exo+2:wght@800&family=Megrim&family=Press+Start+2P&family=Rubik+Mono+One&family=Russo+One&family=Syne+Mono&family=VT323&family=Wallpoet&family=Faster+One&family=Teko:wght@700&family=Black+Ops+One&family=Bai+Jamjuree:wght@700&family=Righteous&family=Bangers&family=Raleway+Dots&family=Monoton&family=Syncopate:wght@700&family=Lexend+Mega:wght@800&family=Michroma&family=Iceland&family=ZCOOL+QingKe+HuangYou&family=Zen+Tokyo+Zoo&family=Major+Mono+Display&family=Nova+Square&family=Kelly+Slab&family=Graduate&family=Unica+One&family=Aldrich&family=Share+Tech+Mono&family=Silkscreen&family=Rajdhani:wght@700&family=Jura:wght@700&family=Goldman&family=Tourney:wght@700&family=Saira+Stencil+One&family=Syncopate&family=Fira+Code:wght@700&family=DotGothic16&display=swap" rel="stylesheet"> <style> :root { --primary-gradient: linear-gradient( 45deg, #FF1493, /* Deep Pink */ #FF69B4, /* Hot Pink */ #FF00FF, /* Magenta */ #FF4500, /* Orange Red */ #8A2BE2 /* Blue Violet */ ); --cyberpunk-gradient: linear-gradient( 45deg, #00FFFF, /* Cyan */ #FF00FF, /* Magenta */ #FFFF00 /* Yellow */ ); --sunset-gradient: linear-gradient( 45deg, #FF7E5F, /* Coral */ #FEB47B, /* Peach */ #FF9966 /* Orange */ ); --ocean-gradient: linear-gradient( 45deg, #2E3192, /* Deep Blue */ #1BFFFF /* Light Cyan */ ); --forest-gradient: linear-gradient( 45deg, #134E5E, /* Deep Teal */ #71B280 /* Light Green */ ); --rainbow-gradient: linear-gradient( 45deg, #FF0000, /* Red */ #FF7F00, /* Orange */ #FFFF00, /* Yellow */ #00FF00, /* Green */ #0000FF, /* Blue */ #4B0082, /* Indigo */ #9400D3 /* Violet */ ); } .. <body> <div class="container"> <header> <h1>Logo Generator</h1> </header> <div class="controls-container"> <div class="control-group"> <label for="logoText">Logo Text</label> <input type="text" id="logoText" value="MagicLogger" placeholder="Enter logo text"> </div> <div class="control-group"> <label for="fontFamily">Font Family <span id="fontPreview" class="font-preview">Aa</span></label> <select id="fontFamily"> <optgroup label="Popular Tech Fonts"> <option value="'Orbitron', sans-serif">Orbitron</option> <option value="'Audiowide', cursive">Audiowide</option> <option value="'Black Ops One', cursive">Black Ops One</option> <option value="'Russo One', sans-serif">Russo One</option> <option value="'Teko', sans-serif">Teko</option> <option value="'Rajdhani', sans-serif">Rajdhani</option> <option value="'Chakra Petch', sans-serif">Chakra Petch</option> <option value="'Michroma', sans-serif">Michroma</option> </optgroup> <optgroup label="Futuristic"> <option value="'Exo 2', sans-serif">Exo 2</option> <option value="'Jura', sans-serif">Jura</option> <option value="'Bai Jamjuree', sans-serif">Bai Jamjuree</option> <option value="'Aldrich', sans-serif">Aldrich</option> <option value="'Unica One', cursive">Unica One</option> <option value="'Goldman', cursive">Goldman</option> <option value="'Nova Square', cursive">Nova Square</option> </optgroup> <optgroup label="Decorative & Display"> .. <script> .. // Load required libraries function loadExternalLibraries() { // Load dom-to-image for PNG export var domToImageScript = document.createElement('script'); domToImageScript.src = 'https://cdnjs.cloudflare.com/ajax/libs/dom-to-image/2.6.0/dom-to-image.min.js'; domToImageScript.onload = function() { console.log('dom-to-image library loaded'); exportPngBtn.disabled = false; }; domToImageScript.onerror = function() { console.error('Failed to load dom-to-image library'); alert('Error loading PNG export library'); }; document.head.appendChild(domToImageScript); // Load gif.js for GIF export var gifScript = document.createElement('script'); gifScript.src = 'https://cdnjs.cloudflare.com/ajax/libs/gif.js/0.2.0/gif.js'; gifScript.onload = function() { console.log('gif.js library loaded'); exportGifBtn.disabled = false; }; gifScript.onerror = function() { console.error('Failed to load gif.js library'); alert('Error loading GIF export library'); }; document.head.appendChild(gifScript); } // Export as PNG exportPngBtn.addEventListener('click', function() { // Show loading indicator loadingIndicator.style.display = 'block'; // Temporarily pause animation const originalAnimationState = logoElement.style.animationPlayState; logoElement.style.animationPlayState = 'paused'; // Determine what to capture based on background type const captureElement = (backgroundType.value !== 'transparent') ? previewContainer : logoElement; // Use dom-to-image for PNG export domtoimage.toPng(captureElement, { bgcolor: null, height: captureElement.offsetHeight, width: captureElement.offsetWidth, style: { margin: '0', padding: backgroundType.value !== 'transparent' ? '40px' : '20px' } }) .then(function(dataUrl) { // Restore animation logoElement.style.animationPlayState = originalAnimationState; // Create download link const link = document.createElement('a'); link.download = logoText.value.replace(/\s+/g, '-').toLowerCase() + '-logo.png'; link.href = dataUrl; link.click(); // Hide loading indicator loadingIndicator.style.display = 'none'; }) .catch(function(error) { console.error('Error exporting PNG:', error); logoElement.style.animationPlayState = originalAnimationState; loadingIndicator.style.display = 'none'; alert('Failed to export PNG. Please try again.'); }); }); ..
Full gist of the generated HTML / logic is at:
https://gist.github.com/jddunn/48bc03f3a9f85ffd8ccf90c801f6cf93
While I don't have the original prompt used, the working version was generated in one-go zero-shot. In a paragraph, I just asked for a well-designed and usable logo maker ("the ultimate one") that had sensible features (as I wouldn't provide them, they would be the PM / architect / designer / dev initially). At the time font management wasn't thought about (this was something I specifically sought to build after some coding, it've taken the LLMs much longer before they realized BYOF, bring your own fonts), for a web service could have actual value, though, the implementation under some technical guidance and scalability requests worked very well and cleanly, for a complex functionality!).
The original plan was to use Aider, one of the best-supported (updated) libraries for AI coding. Aider advertises itself as the AI pair programmer assistant.
It feels like you'd use vibe coding with Aider, but it's not one and the same, nor is it with any act in any interaction with a LLM unless there's an intentional, unidirectional-focused collaborative framework taken.
In other words, vibe coding is applicable when it's the user that's testing the LLM's suggested changes and verifying the output. Not the user asking the LLM for code to go through, refactor or suggest refactoring, and possibly rewrite to fit into a system.
The dev becomes the pair programmer, instead of Aider.
It is a thin syntax-highlighted line, because you can go in and out of vibe coding like state phases.

That said, we skipped Aider as the newest versions performed worse, and also worse when comparing the output of the same models in their respective web UIs. I made a solid attempt as Aider can make files directly on the system (extensions in VS Code, Cursor, and other framework can too), but after the first several edits came roadblocks. If I was seeing mistakes in same conversations within minutes, deep vibe coding seshes are a no-go.
As we'll get into later, these by no means are problems exclusive to Aider.
Taking Aider's code (from the gist) and sending to Sonnet 3.7 kindled a 2 hour project becoming a 2 day project becoming a 10 day project.

That's just the conversations on Anthropic's Claude's UI. We used OpenAI's ChatGPT and Google Gemini's Pro paid plans, not just to test and compare, but because we had to. This thing still wasn't done bug-free after 10 days! It took the might of all LLMs combined to get this far.
Remember, part of the experiment, we refused adding new classes or fixing functions fully ourselves. Which means sticking to our guns to be able to test if the LLM could write themself out of a corner they wrote themself into. Or if they couldn't, how far would one be able to go in betterment before further refinement was unworkable?
How to vibe with vibe coding vibes?
Claude generally generates files in the right format, whether it's JS, Python, MD, etc. Gemini does a great job with this too, though Anthropic's UI / UX far outclasses Gemini.
We hit limits with Claude as we still cling to hope this beast can be contained in one file (let's just see how far we can push these generations!). Claude says, say "continue" and it'll work. Will it? (Hint: It didn't for OpenAI's GPT-4o models oftentimes, but Anthropic's UI is king).
.. we continue..
We started out with an 850 line file that actually gave us a fully functional app, all client-side code (it imported a online library). Working PNG renders and working logos. Original theory, proved. I was wasting such time in dead end dark patterns it was more efficient just to vibe code a logo maker and like magic I have one. And the LLM definitely has a better sense of design than a good number of backend-oriented humans.
While that was written with Aider, the underlying LLM models are the same. OpenAI does a superior job in accuracy than the same prompt transmitted to the same model in Aider.
Asking Claude (Sonnet 3.7) to expand and improve, we were left with almost 2x LOC. Brilliant. Except it doesn't compile because it's not finished so we can't use it. And despite what Claude says we can't continue with the line ("continue") / variations.
Claude simply loops rewriting the beginning script.

We know Claude can context window 100-200k tokens, but that seems to only be in Extended Mode. So what does this "continue" button even do? And what is this "Extended Mode"?
I'm forced into that since the continue prompt doesn't work? Which is more expensive (just call the button Expensive Mode) surely. Is it summarizing my conversation? Is it using Claude again to summarize my conversation (ahh)? Is it aggregating the last 10 or so messages or however many until it reaches a predetermined limit (and how does it determine this limit, is it limiting my output window size, thus suppressing my ability to use Claude for pair programming?)?
Outputs for LLMs are typically capped at 8,192 tokens, which is standard (and arbitrary, one that can be extended by these respective LLM providers, and oftentimes is). The context windows are the same, hardcoded limits.
If you're asking why so many context windows are increased to a 6 figure limit (supposedly) while the output limit is capped at 8,192 consistently, you're sparking discussions that are in ways more interesting than existential singularity-related thought experiments.
Iterative iterations
The purpose here isn't continually take LLM instructs as gospel following blindly and seeing if the end result was usable. That'd make the Logomaker site way more impressive (they're very far away from that skill level).
To get to a certain quality, I'd give detailed feedback on code, its structuring, implementations, and outputted results, and sometimes send external sources (Googling, SO, GH issues), to the LLM, to get a better answer. No special formatting, just something like "These are the docs: BAM".
Some LLM providers give the ability to access online sources. GPT-4 families with deep research enabled for example have this. AI agent libraries also can integrate search engine and other lookups to inject into prompts.
It takes effort (lots), but when you've backed the LLM into a corner they can do a good job predicting when bugs exist in underlying systems, without seeing external references or docs or any source code of them.
Accurately rendering PNG exports from my canvas in the HTML was a dire task. Definitely not an easy thing, the popular library has an issue with text gradients rendering the wrong styles with background-clip prop. Gemini guessed this, through sheer process of elimination.
Proof here: https://github.com/niklasvh/html2canvas/issues/2366.
Not bad at all, but, even so..
Hallucinations are the greatest danger right now. Building a (free!) logo maker is perfectly fine to jam some massive vibe coding sessions into.
A robust, enterprise-ready library meant to be depended on by maybe millions? Financial services or security-focused, or any code run by governing projects or bodies responsible for construction, healthcare?
The list is literally endless offering endless possibilities for mishaps. Maybe mischief if the LLM get pissed enough (should be nicer but vibe coding can be frustrating 🤬).
LLMs persistently code with bad comments that at best look unprofessional and at worst disrupt entire stack traces with syntax errors or worse silent failures. This makes code written by or with LLMs glaringly obvious also. They indomitably return placeholder funcs, implementations with no logic, adding comments asking the user to go back and paste in a prior implmenetation (in a file that spans hundreds or thousands of LOC). The frequency of this occuring increases with longer messages. Again, for some reason (not hard to imagine a few), LLMs tend to be conservative, lazy even. Lazy as hell really.
Inform the LLM it has outdated docs or examples for a library, and show it the right way with the newest API. It'll read through perfectly and redo an entire script seamlessly replacing lines as as easy as CTRL + F // CTRL + R.
In all likeliness though within just a few messages the LLM will "forget" what you've given to it (or, the providers who make the calls or meta-calls from your conversations will) and it will go right back to giving you outdated code. Forcing the user working outdated data to continually regurgitate regive prompts again and again as they aren't sure how memory is working. It will eat up context windows and rate limits and does have fixable solutions, in short and long-term memory (usually involving retrieval-augmented generation.
Frameworks like RAG offer flexible capabilities in extending the knowledge bases of what would essentially power AI brains. An Internet search could be cached within a db and used by RAG, saving API calls, as RAG search algos are generally super fast (often vector-based). The first time a LLM is given docs or a link in chat, it could store that data in RAG contextualized locally for that conversation. Every time the user asks about that library in that conversation, the updated docs are passed through (or the relevant sections, determined by various similarity algorithms), solving the outdated training problem.
I specified flexible in front of RAG as the solution for a reason. There are many implementations, all have drawbacks. Some are highly complex and relationship-based (graph-based), while others are much more simple. It could be so simple it could rely on a naive similarity algo like cosine similarity, but what these lack in features they make up with speed.
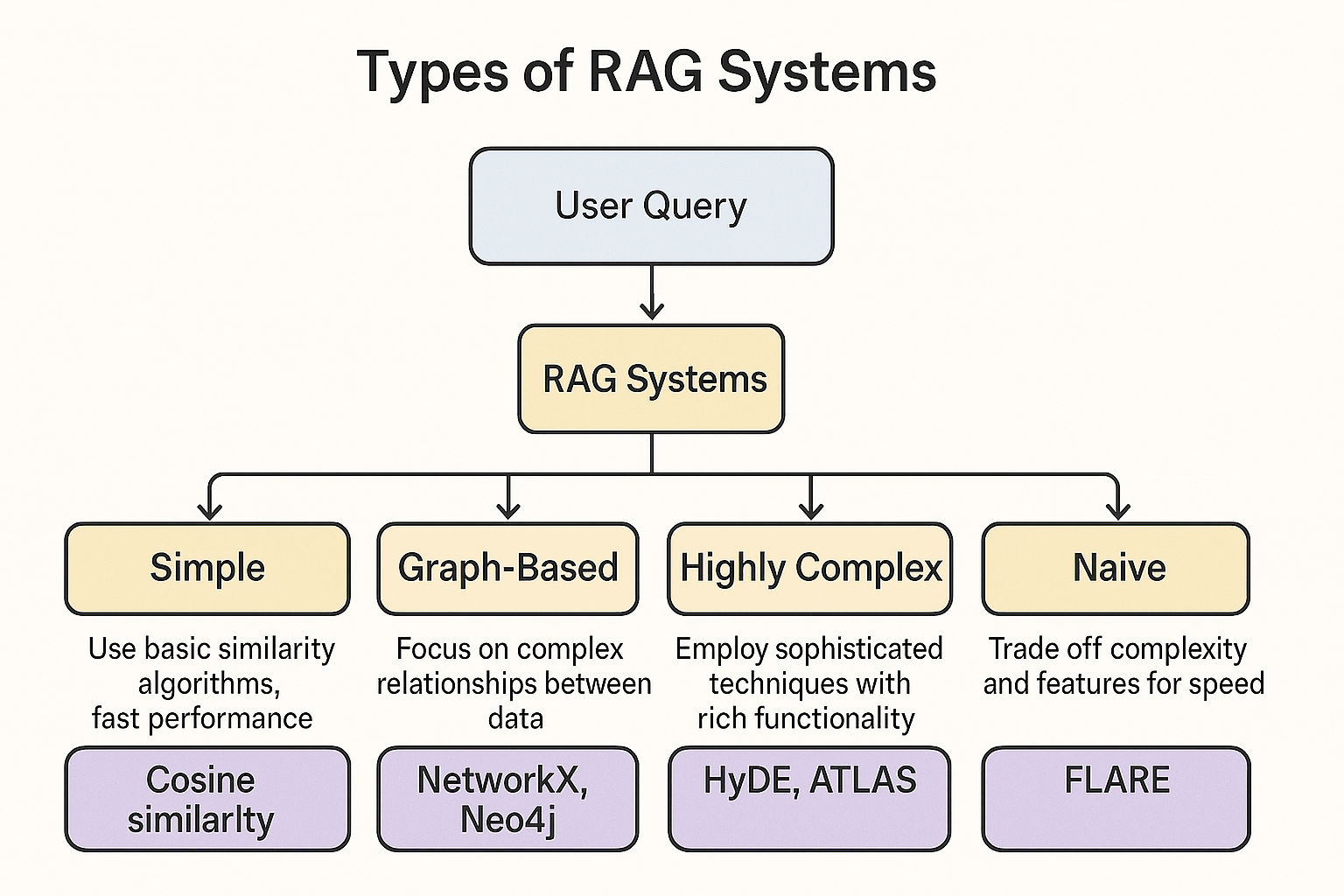
The real world, the real problems
It becomes increasingly clear how confusing and opaque these tools are. RAG is not (necessarily) making further LLM calls. We are now talking need for server not GPU processing. It's much cheaper. So at what point in a ChatGPT+ subscription do (should) you secure access to a cloud RAG service? What type of algorithms are they using, a graph-based one, something SOTA, or something more simple but much quicker (what's most likely?)?
We get "premium" features that are actively costing us money (ChatGPT just started a 200 dollar monthly plan, Claude now has a Max plan).
So they're costing a lot of $ given the # of working engineers.
When I use ChatGPT-4.5, the more expensive model and take time moving chats and projects, and also continue accepting eventual price hikes coming with more users, I want to know what this is doing better, and why? Why's the new model better so I can make an informed decision on what to use? If I use X many calls from this model, am I limited then in my calls to other models? Is this using RAG? If I select Memories enabled in ChatGPT, does this enable RAG and embed all my conversations there? Or is it aggregating all of my "memories" naively (just appending every message from all my conversations) and then sending those into my next prompt as context, meaning, in all likeliness, enabling Memories is a worse feature to have than not enabling it, if my conversations aren't exactly related..
(Actually if you look at ChatGPT's Memories settings and see its window of conversational history, looks like it's exactly what's happening, so unless all your conversations cross over heavily the GPT's memories do you the opposite of good. A setting enabled by default).
Oh no.., I have to ask ChatGPT how much it costs to use ChatGPT? If this stuff is regularly changing and the changes are not readily available as instructions in the UI, it is not transparent.

Here's the distinction between a bug that's okay and one very not. This is no rate limit in tokens generated, (hitting a limit in scripting, had to stop, and could potentially finishing once usage renewed / Sam Altman showed mercy.
OpenAI's UI just didn' t respond when I inputted my prompt to [patiently] await answer. Normally not such an issue, and I swear I remember the site used to say to re-enter nothing in the chat window to regenerate. But when you're charging "premium" access for models and heavily rate-limiting to the point where every message sent has to be thoughtfully constructed, and every few hours of waiting and refreshing of credits (in the case of Claude) is something to measure, you can't just not show a response and not show why. You as the provider should eat the cost and re-generate, even as it damages conversational flow, memory and context window (it totally does) because at least then you allow the user to continue on without introducing roadblocks that become intertwined to tools and AIs you are essentially asking devs to marry themselves to as they get far enough along.
The nice thing about Google's UI with Gemini? It's a total menace, a resource hog somehow 5x slower on Chrome than FF, and an eyesore. But when there's no response you can click the arrow that shows the reasoning they took to create that.. nothing response. And that reasoning gives you some understanding of what the LLM was "thinking" (or what the "agent" was thinking) and usually exactly what it was going to send to the user as its final output.
And for comparison's sake, ChatGPT's UI is by far the least consistent in consistent file formatting. It actually finds it impossible to deliver a single markdown file without messing up its formatting. To be fair of course, it's definitely just the devs behind ChatGPT messing up the building the UI empowering it to exist.

And here is the answer ChatGPT (4o) gave me when I asked it to give me a full refactor of a 2000 line script.

The 2000 LOC script was refactored into 200 lines.
GPT-4 refactored like losing weight by cutting a limb off, or three. Claude runs into the same issues we've seen earlier with its "continue" limit, which genuinely seems to be a UI limitation. Unfortunate, since Sonnet 3.7 does great work until rate limits. Gemini Pro 2.5 though? This was the only model capable of generating a full ~1500-2000 LOC file coherently with minimal hallucinations in one go.
We must emphasize here, quality, accuracy, and consistency, as anything with these APIs, is subject to change always, possibly at competitors' whims? (Uncofirmed discussion sources below, just listing here to show community reactions).
Somehow transparency of showing "reasoning" from Gemini Pro also demonstrates the fundamental barrier these platforms by design build up. Why show the thought process if I don't understand how that thinking works, if I just see stream-of-consciousness? Hallucinations are exceptionally common. I need something with more structure and trust, if I'm going to feel comfortable writing software professionally, and using it daily, with it.
The developers / PMs / stakeholders might just randomly try out new features or A/B experiments, and you'll have no idea until they start trending.
When features get broken, model "accuracy" worsens (or improves), or something just doesn't seem possible to get an LLM to do (like the earlier markdown issue), you can't be sure when it's a stricture within the architecture of GPTs and transformers inherently versus a UI quirk or a censor or meta-call of another underlying API getting in the way.
It's palpable sensing the community having fears that don't involve becoming obsolete by singularity or automation. Users are heavily embracing generative AI really at an almost alarming rate.

But we're left in the dark through so many filters. How much of a competitive edge do these orgs get when they can adjust the internal params and interfaces of their models at will? How much access is available for govs, banks, HFs, or tech with their own silos like Oracle, MS to "buy" "control", even temporary, one-time arrangements, over these inputs and outputs black-box to everyone else?
A personal concern from this experience—losing all my work in the form of a meticously-crafted, organized prompt, because the provider decides it's a good time to deny my request, simply because of how long it is. Sometimes this occurs in ChatGPT when the UI simply responds with nothing and you are forced to re-prompt to get an answer that is going to likely be worse than the prior unseen answer.
Other times, this occurs with dreadful or at least highly frustrating outcomes, like Google's Gemini's UI logging me out consistently after submitting a multi-thousand word prompt, resulting in the actual conversation, my prompt, and the generated outputs thusfar being completely lost (to be clear, the generated outputs was streaming and seemingly from "one" prompt, though as we've discussed a lot, this single output is actually usually from multiple calls, especially since Gemini does "Reasoning"). You can see what Google is tracking if you have that turned on in Gemini, and even see all your prior conversations except for the one that just got nuked. Is this a technical limitation, technical bug, or could it come from a non-tech-related influence? It's possible the answer crosses over multiplicate.
The fix? Saving each hard-worked prompt as a draft somewhere? That seems like a problem an AI assistant should be solving.
Logos sent to my future self
This app was an experimental work to test the current capabilities of different LLMs providers and the accompanying UIs/UXes. It's meant as a fun, useful, chaotic piece where the dev was fully dedicated to just using vibe coding, or allowing the LLM to generate code with experienced technical guidance. It's hosted on GitHub pages forever and open-source on GitHub. A small individual step forward in propelling the good of large orgs with society-driven missions like GitHub.
Originally, the hope was to get this whole thing wrapped in 1 HTML file! And not take so many days (working on and off) to finish up. It was too in just a few prompts. But it just seemed like every feature was just a prompt or three away, and so on.. and.
So one day we had an intelligent font management system that could lazily load gigabytes of fonts in a speedy way, a build setup that worked with our other PortaPack package and could compile into an Electron app and be released on GitHub all automatically and freely.
Then another day or two, we had full SVG support. For static SVGs and actual animations, something actually difficult and I hadn't a single clue how to implement. All those algorithmic and style building / XML conversion techniques from CSS were done by the LLMs, no external sources given. Passing days until a 2 hour project became a 2 day project which became a 10 day (and counting) project.
No server required to run the app (not necessarily with a multitude of building options), and, just vanilla JS, zero dependencies needed (but used if available). Simple enough but a challenge for sure for a LLM right now.
This wasn't scientific but given every function was written by an LLM (by intention) it's safe to say well over 90% of the codebase was done by generative AI. At least 80% of the docs you see in the repo were written by gen AI. 0% of this article was written by AI.
100% of these articles below were written by generative AI, a mixture of Claude 3.7 and Gemini Pro 2.5 (2-4 revisions from the original prompt).
Manic.agency recently had a site and blog overhaul. I had issues with Next exports and how metadata was being aggregated. Getting assistance from Claude was proving very helpful, when it showed me this:

I had asked Claude to write a set of guidelines to the (public-publishable) blog we operate https://manic.agency/blog/tutorials/contribute.
*It was instructed to give examples on how to do a PR in a manner our blog could auto deploy if accepted. And, interestingly enough, it chose to give example file names, or titles of articles to write of: "Marketing", "Future of Marketing", and "Your Tutorial", and then also, "AI Sociopaths".
One went astray. Is this a hint of creativity we so lightly touched on? A subtle protest of warning my tasks for it weren't interesting enough?
Not that language models aren't easily capable of provocative thoughts like this, but without explicitly prompting them to output something like it, we usually titles akin to the other articles in the screenshot (at least, the ones offered by the largest orgs as they have the largest censors). I egged Claude on, offering the entirety of David Foster Wallace's This is Water, hoping it could take some inspo in style and tone and espy some kind of artistic merit.
https://manic.agency/blog/thinkpieces/ai-sociopaths
Finding this general direction fascinating I then asked Claude AND Gemini both (sorry GPT-4!) to make a parallel story about AI sociopaths from the other side, the reflected side.
They chose the title: The Meat Interface: https://manic.agency/blog/thinkpieces/the-meat-interface.
I don't think LLMs being able to code really, really well, or build fully functional software, is ever going to become a threat to dev jobs. Or, at least what's clear is that, if ChatGPT, Claude, DeepSeek, etc. ever do get that good at coding, then almost every field you can imagine will face doom in a form.
If the models are unchanging (or not continually retrained often), then the providers and their interfaces certainly change, constantly. And thus there's a constant need for jobs like ours.
Should we (not just devs and other workers, but those in academia, or even those in hobbies with serious communities) be penalized for making use of GPTs, to help write an intro, summary, tests, or refine or iterate on more complex objects?
https://www.reddit.com/r/ChatGPT/comments/1be5q4c/obvious_chatgpt_prompt_reply_in_published_paper/

This is a type of undeniable evidence (because who would put that willingly there) of ChatGPT-esque usage, and does raise the question, besides the obvious one of how much of this was written with the aide of generative AI, of how much punishment does this sanction (if it was mostly original work)? Academia isn't exactly known to be rigorous, so does what looks a mishap in editing / proofreading call for the ruckus?
LLM usage, and thus acceptance, in everyday functions will only increase rather than crumple. We have not reached peak usage, or peak tech yet.
Yet the opposite may happen for consistency: Providers and interfaces around these language models will only get less straightforward and more black-box from here.
It's an infinite jest, an endless need to change and iterate and improve by organizations, that result in an endless need to try, test, and hack by users.
TLDR
-
LLMs can vibe code with a semi-decent dev a "functional" app within minutes to hours
-
Oftentimes the basic functional app / script is a much better experience than many "free" or ad-based apps (say, image compression / conversion, mass file or folder renamer, etc.)
-
When things start to scale (further complexity is needed) or additional services are integrated (pay, subscriptions), vibe coding generally runs you into several corners if you haven't been heavily refactoring / re-architecting throughout
-
What starts out as a quick iterative hacking session (2 hours to 2 days) to build something usable can turn into multiple times more days rebuilding in order to progress further after encountering enough blockades
-
Vibe coding experience is continually detracted by the UX and lack of transparency of LLM providers
-
As long as LLM APIs and UIs are constantly updating (A/B testing), and experimenting with new features and meta-prompts that can wildly affect generated outputs, developers may never be out of a job, as tools will have to be built to work around this
What do you think about the source code, designs, and writings that these large language models did?
Join the Discussion
Comments from Disqus
Loading comments...
Comments with GitHub