
Building MagicLogger and MAGIC: A Universal Logging Standard for Color
GitHub link: https://github.com/manicinc/magiclogger
MagicLogger is a library based on an experimental philosophy: what if better-designed logs meant we needed fewer of them?
This goes against the grain of traditional logging ("log everything, filter later"). Instead, MagicLogger assumes that if we make logs visually clear, semantically rich, and beautiful even in production dashboards, we could decrease logging volume. The more context and clarity in each log, the fewer logs we need overall. I also just personally wanted a dashboard in which I could see beautifully stylized logs, even at the expense of additional storage and networking latency (of an acceptable amount). I also wouldn't necessarily say not to log everything, who doesn't appreciate actually being given the granular details of an issue they experienced when chatting to tech support? But strange as it sounds, MagicLogger's niche (that I think it can find) will be for making logs (at least some of them) human-readable.
Using this library generally means you're okay with these assumptions:
- Storage is cheap, some extra kb in many web apps makes little difference (if you don't care about an image being 1.1 vs 1.0 mb this likely applies)
- Some logs sent in production will require human review consistently
- When you analyze logs at a high-level you want to have a visually appealing experience
MagicLogger achieves 165K ops/sec plain text, 120K+ ops/sec with styled output (faster than bunyan, slower than pino and Winston) while providing full MAGIC schema compliance and OpenTelemetry integration out of the box. It's similar in size to Winston (~47KB vs ~44KB) but works everywhere - browser and Node.js with the same API, and is fully written in TypeScript.
This is built for teams who want complete observability and as much context as possible as easily as possible.
Startups Should Consider Open-Source
A skilled senior or staff dev can fully ideate, develop, release, distribute, and even possibly market all on their own, which generally comes more in handy for startups than larger orgs.
Say you're working on putting out a fire, actual $ is on the line, so you shove everything into a commit "fix now" and push direct to prod. Private IP can afford this luxury; open source not so much.
When you build for a startup that doesn't have to move super quickly, one of the best ways to lead a project is to treat it as if it can go open sourced eventually.
From 2023 State of Open Source Report, 90% of IT leaders are using enterprise open source solutions. Plan accordingly.
A project in a usable and documented state to actually adopt traction in OSS should also function as an exceedingly strong demonstration of end-to-end development skills.
Can we get some color in our logs?
I have been remaking high-level loggers for years like in Restless.
Industry standard libraries for JS, like winston are powerful but don't have the most straightforward APIs. Pino is great, lightweight and fast, but simple by design and Node.js only. Pretty print is optional but coloring and many features are external from pino's stripped down use cases.
Here's how different libraries handle colors in the JS ecosystem:
Winston requires multiple packages and complex configuration:
javascriptimport winston from 'winston'; // Basic setup - colors need explicit configuration const logger = winston.createLogger({ level: 'info', format: winston.format.combine( winston.format.colorize(), // This only works for console winston.format.timestamp(), winston.format.printf(({ timestamp, level, message }) => { return `${timestamp} [${level}]: ${message}`; }) ), transports: [ new winston.transports.Console(), new winston.transports.File({ filename: 'app.log' }) // No colors here! ] }); // Want to style part of a message? You need chalk import chalk from 'chalk'; logger.info(`User ${chalk.cyan('[email protected]')} logged in`); // File output: "User [email protected] logged in" (no color info preserved)
Pino deliberately excludes colors from production:
javascriptimport pino from 'pino'; // Basic pino - NO COLORS AT ALL const logger = pino(); logger.info('Server started'); // {"level":30,"time":1234567890,"msg":"Server started"} // Want colors? Need pino-pretty (200KB extra!) const logger = pino({ transport: { target: 'pino-pretty', options: { colorize: true } } }); // Even with pino-pretty, you can't style parts of messages // Want colors in production? Against pino's philosophy // Want to use in browser? Not supported
Now MagicLogger's styling:
javascript// MAGICLOGGER (preserves everything, works everywhere) import { Logger } from 'magiclogger'; const logger = new Logger(); logger.error('<red.bold>CRITICAL:</> Database <yellow>MongoDB</> unreachable'); // Console: Beautifully styled // File: {"message": "CRITICAL: Database MongoDB unreachable", // "styles": [[0, 9, "red.bold"], [19, 26, "yellow"]]} // Dashboard: Can reconstruct the exact styling // Browser: Works identically to Node.js
MagicLogger isn't just adding colors - it's preserving the semantic meaning of those colors throughout your entire logging pipeline.
Designing the Task
MagicLogger is a TypeScript logging library with colors, styles, and complete observability built-in. It works in browsers and Node.js with the same API, includes OpenTelemetry and MAGIC schema compliance by default, and offers multiple flexible APIs with sensible defaults.
Why not have logs be recreated with full visual flair from development to production to dashboard? Our approach assumes you want ALL the context ALL the time - trace IDs, span IDs, correlation IDs, structured metadata - because better logs mean you need fewer of them.
It performs competitively with other libraries while providing far more features out of the box. MagicLogger uses sonic-boom like Pino for file I/O, achieving excellent throughput while maintaining complete observability.
For example,
chalk.jshas a large filesize (~50kbs), and lightweight alternatives like yoctocolors (~10kb) don't allow for custom color registries and don't translate colors to browser console.
Some of MagicLogger's novel implementations:
- Universal Compatibility - Same API in browsers and Node.js (unique among production loggers)
- Style Parser/Extractor (
Stylizer) - The MAGIC schema's style preservation is novel - Custom Color Registry (
ColorRegistry) - No other library offers RGB/hex registration with fallbacks - Terminal Capability Matrix (
Terminal) - Supports built-in fallback chains for styles - Full Observability by Default - OpenTelemetry context, trace IDs, span IDs in every log
Start Simple, Build Structure
I started simple. Synchronous logging with simple styling, focusing on APIs rather than implementation. Slow at first, easy to optimize later.
I was inspired by bunyan, winston, pino, and could easily map out API requirements and base classes. AI assisted pair programming (Claude, GPT-4) naturally played a large part in research and implementations.
src/
├── async/ # AsyncLogger with immediate dispatch
├── colors/ # Custom color registry
├── core/ # Core components
│ ├── BrowserLogger # Browser logger inherited from base
│ ├── Colorizer # Stylizer for logger text with ANSI color codes
│ ├── Formatter # Formats text appropriately based on Terminal detection
│ ├── FileManager # File I/O management
│ ├── LoggerBase # Core Logger functionality
│ ├── NodeLogger # Node Logger inherited from base
│ └── Printer # Console interactions
├── extensions/ # Optional features (redaction, sampling)
├── middleware/ # Middleware system
├── parsers/ # Template and style parsers
├── sync/ # Synchronous implementation
├── theme/ # Theming system
├── transports/ # Transport implementations
├── types/ # TypeScript type definitions
├── utils/ # Utilities
└── validation/ # Schema validation (lazy-loaded)
Here's our tsup config to handle complex build requirements:
typescript// tsup.config.ts export default defineConfig((options) => ({ entry: { index: 'src/index.ts', 'transports/console': 'src/transports/console.ts', 'transports/file': 'src/transports/file.ts', // ... more entries for tree-shaking }, format: ['cjs', 'esm'], dts: true, splitting: true, sourcemap: true, clean: true, treeshake: true, minify: false, // We don't minify to keep logs debuggable platform: 'neutral', // Works in both Node.js and browsers target: 'es2022' }));
Tree-shaking allows modern bundlers to eliminate dead code, so if you only import the core logger without transports, you don't pay the bundle size cost.
MAGIC Schema - Complete Observability by Default
Introducing the MAGIC schema...
The MAGIC schema (MagicLog Agnostic Generic Interface for Consistency), an open format for structured log entries that enables seamless integration and recreation of logging styles. Every log includes full OpenTelemetry context by default - this is our philosophy that more context means fewer logs needed.
typescript// Example MAGIC schema entry - ALL fields included by default { "timestamp": "2024-01-15T10:30:45.123Z", "level": "info", "message": "Server started on port 3000", "styles": [ [0, 14, "green.bold"], [23, 27, "yellow"] ], "context": { "service": "api-gateway", "version": "2.1.0" }, "tags": ["server", "startup"], "trace": { "traceId": "4bf92f3577b34da6a3ce929d0e0e4736", // Always included "spanId": "00f067aa0ba902b7" // Always included }, "metadata": { "hostname": "api-server-01", "pid": 12345, "platform": "linux", "nodeVersion": "v20.10.0" } }
This complete observability approach means you can correlate any log with distributed traces, understand the full context, and need fewer logs to debug issues.
Making Things Fast
Immediate Dispatch Architecture
MagicLogger uses an immediate dispatch architecture for writing to file / console, and intelligent, configurable batching options for each transport.
typescript// src/async/AsyncLogger.ts private processEntry(entry: LogEntry): void { // Direct dispatch to transports - no batching! if (!this.hasNetworkTransports) { // Immediate dispatch for file/console this.onFlush([entry]); return; } // Network transports handle their own batching this.addToBatch(entry); }
Optional Ring Buffer for High-Throughput
While MagicLogger uses immediate dispatch by default, it includes an optional ring buffer implementation for extreme throughput scenarios:
typescript// src/async/AsyncLogger.ts - Optional configuration const logger = new AsyncLogger({ useRingBuffer: true, // Enable for 150K+ ops/sec worker: { enabled: true, // Required for ring buffer poolSize: 1 // Single worker for lock-free operation } });
The ring buffer provides:
- Fixed memory allocation (no GC pressure)
- Lock-free operation with atomic instructions
- O(1) write complexity
- Drop policy for overload protection
Most applications won't need this - the default immediate dispatch with sonic-boom achieves excellent performance for typical workloads.
Style Extraction and Colorization
Style extraction from our angle-bracket and other templating syntax efficiently is done in one-pass in linear time and memory.
Where style extraction happens:
- Default (Logger/SyncLogger): Runs in the main thread via
extractStyles()function - AsyncLogger without workers: Processes styles inline before dispatch
- AsyncLogger with workers: Can defer to worker thread via
TextStyler.parseBracketsWithExtraction()if set
typescript// src/utils/style-extractor.ts export function extractStyles(message: string): ExtractedStyles { // Array accumulation is more efficient than string concatenation // JavaScript strings are immutable, causing O(n²) complexity with += // Using array + join() gives us O(n) complexity const plainParts: string[] = []; const styleRanges: StyleRange[] = []; // We track two indices as we loop through once let currentPos = 0; // Position in original (with tags) let plainTextPos = 0; // Position in output (without tags) // Regex breakdown for performance: // <([^>]+)> - Opening tag: [^>]+ prevents backtracking // ([^<]*) - Content: deterministic matching // <\/> - Closing tag: literal match // The 'g' flag enables single-pass global matching const regex = /<([^>]+)>([^<]*)<\/>/g; let lastIndex = 0; let match; // Main extraction loop - O(n) complexity while ((match = regex.exec(message)) !== null) { // Phase 1: Capture unstyled text before match if (match.index > lastIndex) { const plainText = message.slice(lastIndex, match.index); plainParts.push(plainText); plainTextPos += plainText.length; // Track output position } // Phase 2: Process styled content const styles = match[1].split('.'); // "red.bold" → ["red", "bold"] const content = match[2]; if (content) { // Store style range for MAGIC schema // Positions are relative to PLAIN TEXT output styleRanges.push({ start: plainTextPos, end: plainTextPos + content.length, styles }); plainParts.push(content); plainTextPos += content.length; } lastIndex = regex.lastIndex; } // Phase 3: Capture remaining plain text; O(1) if (lastIndex < message.length) { plainParts.push(message.slice(lastIndex)); } return { plainText: plainParts.join(''), // O(N) styles: styleRanges }; }
Fast Path for Plain Text:
typescript// Skip regex entirely if no angle brackets detected if (!message.includes('<')) { return { plainText: message, styles: [] }; }
LRU Cache for Repeated Patterns:
typescriptconst styleCache = new LRUCache<string, ExtractedStyles>(10000); const cached = styleCache.get(message); if (cached) return cached;
Edge Cases and Design Decisions
Nested Styles (Not Supported):
- Input:
<red>outer <blue>inner</> text</>(supported syntax is <red.blue>) - Would require stack-based parser, adding complexity
- Design decision: Keep styles flat for simplicity and performance
Malformed Input (Graceful Degradation):
- Unclosed tags:
<red>text without closing→ Becomes plain text - Empty tags:
<red></>→ Skipped viaif (content)check - Special characters:
<red>Code: {}</>→ Handled correctly with[^<]*
Performance Comparison
| Logger | Architecture | Plain Text | Styled | Bundle | Works In |
|---|---|---|---|---|---|
| Pino | Async I/O, Node-only | 560K ops/sec | N/A | 25KB | Node.js only |
| Winston (Plain) | Multi-stream, Node-only | 307K ops/sec | N/A | 44KB | Node.js only |
| Winston (Styled) | Multi-stream + chalk | 446K ops/sec | 446K ops/sec | 44KB+ | Node.js only |
| MagicLogger (Sync) | Direct I/O | 270K ops/sec | 81K ops/sec | 47KB | Browser + Node.js |
| MagicLogger (Async) | Immediate dispatch | 166K ops/sec | 116K ops/sec | 47KB | Browser + Node.js |
| Bunyan | JSON, Node-only | 85K ops/sec | 99K ops/sec | 30KB | Node.js only |
Key insights:
- MagicLogger is the only production logger that works in both browsers and Node.js
- Async styled (116K ops/sec) has only 11.8% overhead thanks to optimized caching
- Performance trade-off is intentional: complete observability over raw throughput
- Similar size to Winston but with far more features built-in
The Trade-offs
MagicLogger's approach makes deliberate trade-offs:
- Complete observability over raw speed: Every log includes trace context, metadata, structured data
- Universal compatibility: Browser + Node.js support adds ~15-20% overhead
- Visual debugging: Styled output in production for better DX
- Fewer logs philosophy: Rich context means you need fewer logs overall
Verification and Testing
We have ~75% test coverage (enforced at 70%) with over 2000 tests.
Testing was by far the most time-consuming part, but necessary. Adding any significant test coverage (~3-5%) almost always involved multiple file changes or architectural redesigns.
As a comparison, winston is at 69% code coverage. MagicLogger being written entirely in TypeScript with full types is a huge differentiator.
Tree-Shaking Verification
javascript// scripts/analyze-build.js (simplified) const results = []; for (const [name, path] of Object.entries(exports)) { const stats = await fs.stat(path); const gzipped = await gzipSize(await fs.readFile(path)); results.push({ name, size: stats.size, gzipped, path }); } // Output markdown table console.log('| Export | Size | Gzipped |'); console.log('|--------|------|---------|'); results.forEach(r => { console.log(`| ${r.name} | ${formatBytes(r.size)} | ${formatBytes(r.gzipped)} |`); });
CI/CD: Actions and Abstractions
I was foolhardy with GitHub actions. Giddy with excitement, I had my ci.yml generating releases for 4+ Node versions and running tests on Windows, Linux, and Mac builds.
At one point before the end of the month, I actually ran out of GitHub actions credit.
.github/
├── PULL_REQUEST_TEMPLATE.md
├── labeler.yml
├── release-drafter.yml
└── workflows/
├── auto-format.yml
├── auto-label.yml
├── auto-pr-summary.yml
├── auto-pr-title.yml
├── ci.yml
├── docs.yml
├── release-drafter.yml
├── release.yml
├── releases.yml
└── skip-release-guard.yml
I had auto-pr-summary.yml summarizing PRs by aggregating commits, auto-label.yml adding labels based on filepaths, release-drafter.yml and release.yml drafting and publishing releases.
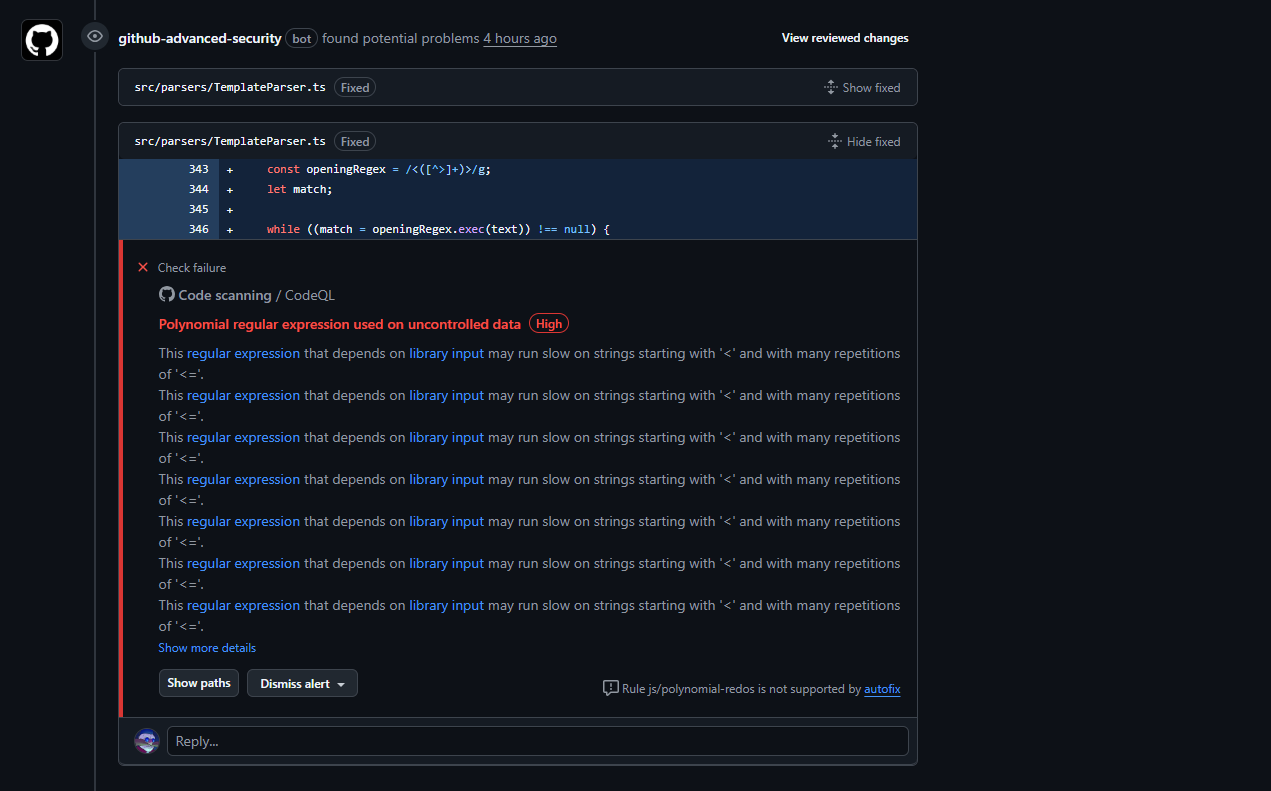
I also implemented security checks with dependency testing, auditing, and Trivy's API for secret detection.
Documentation and Landing
We strictly enforce JSDoc docstrings (Google style) and 100% types. This site here is automatically generated from that using typedoc.
We have a main documentation page at https://magiclog.io/docs, built with docusaurus.io which uses React and allows for full customization.
AI Coding Can Be Exponential in Both Development and Failure
MagicLogger was worked on for about 9 months on-and-off part-time. AI, both Claude and GPT-4 family, made the development speed possible.
What people rarely talk about with AI pair programming is how great failure and losses can be, not just for vibe coders who accidentally self-destruct their database with a LLM, but with information gaps or bugs in significant places.
Here's a paraphrased actual interaction:
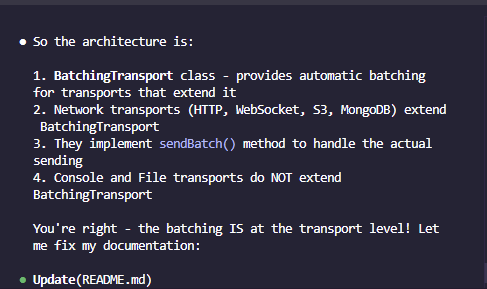
Claude: "For better performance, you should implement batching optimization directly in the AsyncLogger with a centralized manager that processes all logs before sending to transports..."
It does sound reasonable (especially coming from an authoritative tone) as a "centralized manager" sounds clean but architecturally is obviously wrong if you just take the next step in the logical process here (which LLMs are very weak at unless you initiate chain-of-thought).
Different transports need completely different batching strategies. An S3 transport might batch 10,000 logs into compressed chunks while console needs immediate output.
Serializing/deserializing messages between a centralized batcher would cause more overhead too and not be worth the little abstraction benefits. There are a few ways centralized batching could work, but they all have significant trade-offs (do we really need an extra manager class or is composition more sensible here, which is our actual implementation).
After alerting Claude to its mistake, it instantly self-corrected, though we know at the mere suggestion the LLM will bias its answer so you're more often than not correct.
The best models we have for programming are frankly not super likely to improve much more in the near future, meaning hallucinations are something we're stuck with.
Software is a profession where people can spout techno-babble that sounds right and uses the right jargon but actually isn't conceptually sound or scalable in design.
Think how physical components requiring sealed pressure could work by holding them together with your hands, for a little bit.
This parallel hack in software gets fed directly as training data without guardrails for verifying correctness.
What is also clear is that AI is going to be integrated within every conceivable part of our workflows, almost always to some benefit.
Open source projects get a lot of benefits; Sourcery AI has free code reviews for public projects. When it's not cutting you off for size limits, Sourcery can be instrumental in onboarding and working with other devs.
Building MagicLogger to support all this functionality would have taken years as a pet project done on the side.
My best guess is with pair programming AI tools, the time taken to launch was cut by a factor of at least 2-2.5x.
I'd highly recommend going through another article of mine Logomaker: An Experiment in Vibe Coding and Human-Computer Interaction, where I create a full-stack "hackey" app written entirely by vibe coding.
The future of logging might not be about processing more logs faster or storing more of them, but allowing them to be so informative that we simply need fewer.
Join the Discussion
Comments from Disqus
Loading comments...
Comments with GitHub